{tocify} $title={Table of Contents}
For demo I am using simple scenario - moving data from Azure SQL to Azure Data Lake Store. Continued from last post(Getting Started with Azure Data Factory - CopyData from CosmosDB to SQL)

But here, upon failure details are logged into custom monitoring table

Small mistake here which led to failure in Pipeline run.

Small mistake here which led to failure in Pipeline run.
Based on what all details you need to capture, number of columns can be defined. For demo twelve entities are identified thus those are added as columns in ErrorLogTable

And a simple stored procedure to insert values in it
CREATE PROCEDURE [dbo].[usp_UpdateErrorLogTable]
@PipelineName VARCHAR(250),
@PipelineID VARCHAR(250),
@Source VARCHAR(300),
@ActivityName VARCHAR(250),
@ActivityID VARCHAR(250),
@ErrorCode VARCHAR(10),
@ErrorDescription VARCHAR(5000),
@FailureType VARCHAR(50),
@ActivityStartTime DATETIME,
@PipelineStartTime DATETIME,
@BatchID VARCHAR(100),
@ErrorLoggedTime DATETIME,
AS
BEGIN
DECLARE @CheckError INT = 0;
BEGIN TRY
INSERT INTO [ErrorLogTable]
(
[PipelineName],
[PipelineID],
[Source],
[ActivityName ],
[ActivityID ],
[ErrorCode ],
[ErrorDescription ],
[FailureType ],
[ActivityStartTime ],
[PipelineStartTime ],
[BatchID ],
[ErrorLoggedTime ]
)
VALUES
(
@PipelineName ,
@PipelineID ,
@Source ,
@ActivityName ,
@ActivityID ,
@ErrorCode ,
@ErrorDescription ,
@FailureType ,
@ActivityStartTime ,
@PipelineStartTime ,
@BatchID ,
@ErrorLoggedTime
)
END TRY
BEGIN CATCH
SET @CheckError = ERROR_NUMBER()
END CATCH
IF @CheckError = 0
BEGIN
RETURN 1
END
ELSE
BEGIN
RETURN -1
END
END
i. To create new instance of Data Factory, login to Azure portal Click on +Create a resource --> Data Factories --> click on +Add button
Select * from EmployeeArchive1 where Jobtitle='Developer'

After the pipeline run completed, entries were found in the ErrorLogTable

Introduction
Monitoring of any system/application's health and performance plays very important role in an Enterprise , as you get insight about what is happening with the applications and can prevent from major losses by enabling better/corrective decision.
Microsoft has provided inbuilt Monitoring feature within Azure Data Factory where you gets details about the each Pipeline which is run and also details about the activity inside the pipeline.


and at activity level you can even see input and output of that particular activity.
1. Currently the pipeline run data retention is only for 45 days, then after data would be no more available.
2. Support for User defined properties -- all the details which we see is system properties but what about other than those, i.e. User defined properties which we want to monitor (non system). Yes, there is support to include User Properties in Monitor - you can promote any pipeline activity property as a user property( But only 5).
3. And not all properties are shown in Monitor tab.However columns can be added or removed but are limited and only available for pipeline run and not for activity run.
Microsoft has provided inbuilt Monitoring feature within Azure Data Factory where you gets details about the each Pipeline which is run and also details about the activity inside the pipeline.

As can be seen lot of details are made available at both the levels,RunID, Starttime, status, name, duration etc.

and at activity level you can even see input and output of that particular activity.
So the question might arise why need of Custom monitoring table?
1. Currently the pipeline run data retention is only for 45 days, then after data would be no more available.
2. Support for User defined properties -- all the details which we see is system properties but what about other than those, i.e. User defined properties which we want to monitor (non system). Yes, there is support to include User Properties in Monitor - you can promote any pipeline activity property as a user property( But only 5).
3. And not all properties are shown in Monitor tab.However columns can be added or removed but are limited and only available for pipeline run and not for activity run.
Scenario:
For demo I am using simple scenario - moving data from Azure SQL to Azure Data Lake Store. Continued from last post(Getting Started with Azure Data Factory - CopyData from CosmosDB to SQL)

But here, upon failure details are logged into custom monitoring table
Steps in creating solution
Create Azure Data Lake Store -- Destination

Small mistake here which led to failure in Pipeline run.
Create Azure SQL DB -- Source

Small mistake here which led to failure in Pipeline run.
Create Error Logging Table and Stored Procedure to Insert values in it
Based on what all details you need to capture, number of columns can be defined. For demo twelve entities are identified thus those are added as columns in ErrorLogTable

And a simple stored procedure to insert values in it
CREATE PROCEDURE [dbo].[usp_UpdateErrorLogTable]
@PipelineName VARCHAR(250),
@PipelineID VARCHAR(250),
@Source VARCHAR(300),
@ActivityName VARCHAR(250),
@ActivityID VARCHAR(250),
@ErrorCode VARCHAR(10),
@ErrorDescription VARCHAR(5000),
@FailureType VARCHAR(50),
@ActivityStartTime DATETIME,
@PipelineStartTime DATETIME,
@BatchID VARCHAR(100),
@ErrorLoggedTime DATETIME,
AS
BEGIN
DECLARE @CheckError INT = 0;
BEGIN TRY
INSERT INTO [ErrorLogTable]
(
[PipelineName],
[PipelineID],
[Source],
[ActivityName ],
[ActivityID ],
[ErrorCode ],
[ErrorDescription ],
[FailureType ],
[ActivityStartTime ],
[PipelineStartTime ],
[BatchID ],
[ErrorLoggedTime ]
)
VALUES
(
@PipelineName ,
@PipelineID ,
@Source ,
@ActivityName ,
@ActivityID ,
@ErrorCode ,
@ErrorDescription ,
@FailureType ,
@ActivityStartTime ,
@PipelineStartTime ,
@BatchID ,
@ErrorLoggedTime
)
END TRY
BEGIN CATCH
SET @CheckError = ERROR_NUMBER()
END CATCH
IF @CheckError = 0
BEGIN
RETURN 1
END
ELSE
BEGIN
RETURN -1
END
END
Create Azure Data Factory and Pipeline
i. To create new instance of Data Factory, login to Azure portal Click on +Create a resource --> Data Factories --> click on +Add button
Provide unique name to Data Factory instance to be created as per purpose , select the subscription, resource group, version and location(Note that currently only limited locations are available to choose from).
{kind=link}
After creating an instance of Data Factory, you need to click on Author and Monitor - which will lead to ADF designer portal (dev env) which opens in separate tab.


{kind=link}
The new tab opens with options to get started with. Either click on Create Pipeline Wizard or the Pencil icon, both will lead to the canvas.
ii. If you already have Data Factory instance, you can skip above step.

Search and open existing ADF instance and add new pipeline in it.
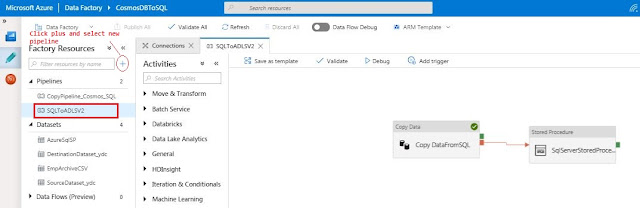
iii. Create Linked Service and Dataset which will be used in pipeline.
SQL Linked service and dataset

Go to Connection tab and click on New button. Give it a name, database details, username, password etc.

ADLS Linked service and dataset


iv. Now drag and drop Copy activity from Activities-->Move & Transform section on canvas
 Give it a name, select Dataset (SQL Dataset created in above step) and the query to fetch data
Give it a name, select Dataset (SQL Dataset created in above step) and the query to fetch data

ii. If you already have Data Factory instance, you can skip above step.

Search and open existing ADF instance and add new pipeline in it.

iii. Create Linked Service and Dataset which will be used in pipeline.
SQL Linked service and dataset


Here no Table is selected, as am going to use query(Note: Even if you choose table here, you can use query in the activity).

Go to Connection tab and click on New button. Give it a name, ADLS url, account key.

iv. Now drag and drop Copy activity from Activities-->Move & Transform section on canvas


In sink tab select Dataset (ADLS dataset created in above step)
v. Now next step is to add StoredProcedure activity on canvas and connect Copy DataFromSQL activity to it but on failure condition.

Select Copy DataFromSQL activity and Click on plus sign and select Failure.

Under general tab give name and under SQL Account select the Linked Service, here we are using same Linked service which was created to SQL DB.

Under Stored Procedure tab select the SP and click on Import Parameter button -- It will fetch list of all the parameters defined in SP. You can add parameters manually too by pressing +New button.

Here am capturing details of Activity and Pipeline from properties which are promoted by system at runtime (ActivityID, PipelineID, ErrorCode etc.) and few are static values (User defined properties e.g., Source and ActivityName).
v. Now next step is to add StoredProcedure activity on canvas and connect Copy DataFromSQL activity to it but on failure condition.

Select Copy DataFromSQL activity and Click on plus sign and select Failure.

Under general tab give name and under SQL Account select the Linked Service, here we are using same Linked service which was created to SQL DB.

Under Stored Procedure tab select the SP and click on Import Parameter button -- It will fetch list of all the parameters defined in SP. You can add parameters manually too by pressing +New button.

Here am capturing details of Activity and Pipeline from properties which are promoted by system at runtime (ActivityID, PipelineID, ErrorCode etc.) and few are static values (User defined properties e.g., Source and ActivityName).
How it works
Whenever pipeline is triggered a RunID gets assigned to it and also to each activities within it , also other info like PipelineName, JobId, ActivityRunId, Status, StatusCode, Output, Error, ExecutionStartTime, ExecutionEndTime, ExecutionDetails, Duration and many more are captured. But all are not accessible, only few of them are, the ones which are promoted by system(available to access). And to access them we need to use accessors(properties).
example -
a. to get Pipeline ID use RunID property of Pipeline class -- pipeline().RunId
b. to get when particular activity started use ExecutionStartTime property of activity class -- activity('name of activity').ExecutionStartTime
c. to get the error details of particular activity use error.message property of activity class -- activity('name of activity').error.message (it is available only if that particular activity has failed).
That's it, pipeline is ready, validate it , publish it and test.
example -
a. to get Pipeline ID use RunID property of Pipeline class -- pipeline().RunId
b. to get when particular activity started use ExecutionStartTime property of activity class -- activity('name of activity').ExecutionStartTime
c. to get the error details of particular activity use error.message property of activity class -- activity('name of activity').error.message (it is available only if that particular activity has failed).
That's it, pipeline is ready, validate it , publish it and test.
Testing
The copy activity has to fail so that entry is made in ErrorLogTable, for that provided Incorrect table name in Query

After the pipeline run completed, entries were found in the ErrorLogTable
{kind=link}

If you have questions or suggestions, feel free to do in comments section below !!!
Do share if you find this helpful .......
Knowledge Sharing is Caring !!!!!!
Learn More about Azure Data Factory
- Getting started with ADF - Loading data in SQL Tables from multiple parquet files dynamically
- Getting started with ADF - Creating and Loading data in parquet file from SQL Tables dynamically
- Getting Started with Azure Data Factory - Insert Pipeline details in Custom Monitoring Table
- Getting Started with Azure Data Factory - CopyData from CosmosDB to SQL
Tags:
Azure Data Factory
@activity('at_look_business_account').Error.message why this is not working for me
ReplyDelete{
"errorCode": "InvalidTemplate",
"message": "The expression 'activity('at_look_business_account').Error.message' cannot be evaluated because property 'message' cannot be selected.",
"failureType": "UserError",
"target": "Stored Procedure1",
"details": ""
}